
Kali ini saya akan menjelaskan sedikit tentang Sentiment Analysis yang dilakukan pada aplikasi twitter dengan menggunakan bahasa R.
Pertama-tama download software R yang akan kita gunakan. Agar lebih ringan saya merekomendasikan aplikasi CRAN R-Project daripada Rstudio.
Setelah di download install package yang diperlukan untuk melakukan sentiment analysis. Buka CRAN R-Project lalu ketikkan seperti kode dibawah :
install.packages('twitteR')
install.packages('RCurl')
install.packages('wordcloud')
install.packages('corpus')
install.packages('tm')
Setelah terinstal, aktifkan semua package/modul tersebut dengan cara seperti dibawah :\
require(twitteR)
require(wordcloud)
require(corpus)
require(tm)
require(RCurl)
Untuk dapat melalukan mining pada twitter maka kita membutuhkan sebuah token dan api twitternya dengan merequest pada https://apps.twitter.com/ lalu kita akan mengambil beberapa kode diantaranya consumer Key(API), consumer secret(API Secret), Access Token dan Access Token Secret. Jangan lupa untuk login menggunakan akun twitter yang kita punya.
Setelah login lalu pilih create new app. Lalu isikan appnamenya, deskripsinya dan masukkan juga website kalian dan setelah itu jangan lupa di ceklis pada bagian developer agreementnya.


access_token <- 'isi dengan Access Token'
access_secret <- 'isi dengan Access Secret'
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_secret)

Pertama-tama download software R yang akan kita gunakan. Agar lebih ringan saya merekomendasikan aplikasi CRAN R-Project daripada Rstudio.
Setelah di download install package yang diperlukan untuk melakukan sentiment analysis. Buka CRAN R-Project lalu ketikkan seperti kode dibawah :
install.packages('twitteR')
install.packages('RCurl')
install.packages('wordcloud')
install.packages('corpus')
install.packages('tm')
Setelah terinstal, aktifkan semua package/modul tersebut dengan cara seperti dibawah :\
require(twitteR)
require(wordcloud)
require(corpus)
require(tm)
require(RCurl)
Untuk dapat melalukan mining pada twitter maka kita membutuhkan sebuah token dan api twitternya dengan merequest pada https://apps.twitter.com/ lalu kita akan mengambil beberapa kode diantaranya consumer Key(API), consumer secret(API Secret), Access Token dan Access Token Secret. Jangan lupa untuk login menggunakan akun twitter yang kita punya.
Setelah login lalu pilih create new app. Lalu isikan appnamenya, deskripsinya dan masukkan juga website kalian dan setelah itu jangan lupa di ceklis pada bagian developer agreementnya.

Setelah kalian isi, kalian akan mendapatkan kode-kode yang dibutuhkan tadi seperti gambar dibawah

Lalu setelah itu, kembali masuk ke CRAN RProject, lalu ketikkan kode berikut :
consumer_key <- 'isi dengan Consumer Key'
consumer_secret <- 'isi dengan Consumer Secret'access_token <- 'isi dengan Access Token'
access_secret <- 'isi dengan Access Secret'
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_secret)
Ketikkan seperti diatas setelah itu jalankan kodenya, fungsi diatas adalah membuat variabel untuk menyimpan kode-kode tadi yang akan digunakan sebagai autentikasi twitter agar R kita dapat mengakses twitter kita.
Setelah itu, buatlah variabel baru lagi untuk memanggil fungsi search twitter seperti dibawah :
miningtweets <- searchTwitter('anak+tolol', lang="id", n=500,resultType="recent")
Search pada Twitter akan mencari keyword 'anak tolol' dalam bahasa Indonesia sebanyak 500 tweets dan kondisi yang baru saja terjadi.
Setelah itu akan muncul warning seperti gambar dibawah
Warning message:
In doRppAPICall("search/tweets", n, params = params, retryOnRateLimit = retryOnRateLimit, :
500 tweets were requested but the API can only return 144
Jika seperti ini maka mining data berhasil dan data sudah didapatkan oleh R. Setelah itu masukkan kode seperti dibawah :
bully_corpus <- Corpus(VectorSource(miningtweets_text))
inspect(bully_corpus)
Setelah data dikumpulkan maka akan keluar output seperti gambar dibawah :

Jika sudah maka kita tinggal memberikan filter pada hasil searching tersebut dengan kode dibawah :
kasar_clear<-tm_map(bully_corpus, removePunctuation)
kasar_clear<-tm_map(kasar_clear, removeNumbers)
kasar_clear<-tm_map(kasar_clear, stripWhitespace)
kasar_clear<-tm_map(kasar_clear, removeWords,c("anak"))
Baris pertama untuk menghilankan tanda baca
Baris kedua untuk mengilangkan angka
Baris ketiga untuk menghilangkan spasi
Baris keempat untuk menghilangkan kata 'anak'
Lalu kita akan menampilkan hasilnya dengan menggunakan kode dibawah :
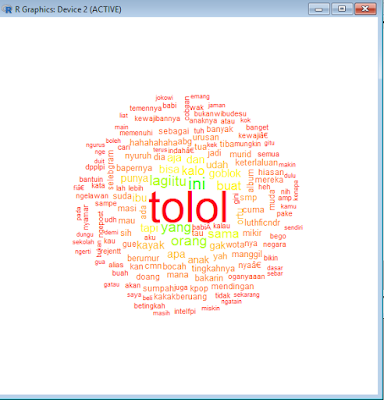
wordcloud(kasar_clear, random.order=F, col=rainbow(50))
Kode tersebut digunakan untuk memanggil hasil pencarian tadi dengan kondisi dimana kata yang terbanyak akan ditempakan ditengah dan besar dan akan memberikan warna-warni pada hasilnya.
Berikut adalah hasilnya

Anggota Kelompok :
Andi Muhadir Amin
Bisma Dwiki Ananda Tomy
Henggar Tri W
Lungguh Syam P
4IA10
Sentiment Analysis pada Twitter dengan R
Kali ini saya akan menjelaskan sedikit tentang Sentiment Analysis yang dilakukan pada aplikasi twitter dengan menggunakan bahasa R.
Pertama-tama download software R yang akan kita gunakan. Agar lebih ringan saya merekomendasikan aplikasi CRAN R-Project daripada Rstudio.
Setelah di download install package yang diperlukan untuk melakukan sentiment analysis. Buka CRAN R-Project lalu ketikkan seperti kode dibawah :
install.packages('twitteR')
install.packages('RCurl')
install.packages('wordcloud')
install.packages('corpus')
install.packages('tm')
Setelah terinstal, aktifkan semua package/modul tersebut dengan cara seperti dibawah :\
require(twitteR)
require(wordcloud)
require(corpus)
require(tm)
require(RCurl)
Untuk dapat melalukan mining pada twitter maka kita membutuhkan sebuah token dan api twitternya dengan merequest pada https://apps.twitter.com/ lalu kita akan mengambil beberapa kode diantaranya consumer Key(API), consumer secret(API Secret), Access Token dan Access Token Secret. Jangan lupa untuk login menggunakan akun twitter yang kita punya.
Setelah login lalu pilih create new app. Lalu isikan appnamenya, deskripsinya dan masukkan juga website kalian dan setelah itu jangan lupa di ceklis pada bagian developer agreementnya.
access_token <- 'isi dengan Access Token'
access_secret <- 'isi dengan Access Secret'
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_secret)
Pertama-tama download software R yang akan kita gunakan. Agar lebih ringan saya merekomendasikan aplikasi CRAN R-Project daripada Rstudio.
Setelah di download install package yang diperlukan untuk melakukan sentiment analysis. Buka CRAN R-Project lalu ketikkan seperti kode dibawah :
install.packages('twitteR')
install.packages('RCurl')
install.packages('wordcloud')
install.packages('corpus')
install.packages('tm')
Setelah terinstal, aktifkan semua package/modul tersebut dengan cara seperti dibawah :\
require(twitteR)
require(wordcloud)
require(corpus)
require(tm)
require(RCurl)
Untuk dapat melalukan mining pada twitter maka kita membutuhkan sebuah token dan api twitternya dengan merequest pada https://apps.twitter.com/ lalu kita akan mengambil beberapa kode diantaranya consumer Key(API), consumer secret(API Secret), Access Token dan Access Token Secret. Jangan lupa untuk login menggunakan akun twitter yang kita punya.
Setelah login lalu pilih create new app. Lalu isikan appnamenya, deskripsinya dan masukkan juga website kalian dan setelah itu jangan lupa di ceklis pada bagian developer agreementnya.
Setelah kalian isi, kalian akan mendapatkan kode-kode yang dibutuhkan tadi seperti gambar dibawah
Lalu setelah itu, kembali masuk ke CRAN RProject, lalu ketikkan kode berikut :
consumer_key <- 'isi dengan Consumer Key'
consumer_secret <- 'isi dengan Consumer Secret'access_token <- 'isi dengan Access Token'
access_secret <- 'isi dengan Access Secret'
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_secret)
Ketikkan seperti diatas setelah itu jalankan kodenya, fungsi diatas adalah membuat variabel untuk menyimpan kode-kode tadi yang akan digunakan sebagai autentikasi twitter agar R kita dapat mengakses twitter kita.
Setelah itu, buatlah variabel baru lagi untuk memanggil fungsi search twitter seperti dibawah :
miningtweets <- searchTwitter('anak+tolol', lang="id", n=500,resultType="recent")
Search pada Twitter akan mencari keyword 'anak tolol' dalam bahasa Indonesia sebanyak 500 tweets dan kondisi yang baru saja terjadi.
Setelah itu akan muncul warning seperti gambar dibawah
Warning message:
In doRppAPICall("search/tweets", n, params = params, retryOnRateLimit = retryOnRateLimit, :
500 tweets were requested but the API can only return 144
Jika seperti ini maka mining data berhasil dan data sudah didapatkan oleh R. Setelah itu masukkan kode seperti dibawah :
bully_corpus <- Corpus(VectorSource(miningtweets_text))
inspect(bully_corpus)
Setelah data dikumpulkan maka akan keluar output seperti gambar dibawah :
Jika sudah maka kita tinggal memberikan filter pada hasil searching tersebut dengan kode dibawah :
kasar_clear<-tm_map(bully_corpus, removePunctuation)
kasar_clear<-tm_map(kasar_clear, removeNumbers)
kasar_clear<-tm_map(kasar_clear, stripWhitespace)
kasar_clear<-tm_map(kasar_clear, removeWords,c("anak"))
Baris pertama untuk menghilankan tanda baca
Baris kedua untuk mengilangkan angka
Baris ketiga untuk menghilangkan spasi
Baris keempat untuk menghilangkan kata 'anak'
Lalu kita akan menampilkan hasilnya dengan menggunakan kode dibawah :
wordcloud(kasar_clear, random.order=F, col=rainbow(50))
Kode tersebut digunakan untuk memanggil hasil pencarian tadi dengan kondisi dimana kata yang terbanyak akan ditempakan ditengah dan besar dan akan memberikan warna-warni pada hasilnya.
Berikut adalah hasilnya
Sentiment Analysis
PENDAHULUAN
Pada
masa sekarang, pengolahan data-data harus diolah secara efisien dan efektif.
Dimana sebuah data yang ada harus dihasilkan dengan hasil yang akurat dan
cepat. Semakin banyaknya data-data yang digunakan maka proses pengolahannya pun
akan menjadi lebih lama. Lalu, ada sebuah ide dari beberapa fisikawan antara lain Charles H.
Bennett dari IBM, Paul A. Benioff dari Argonne National Laboratory, Illinois,
David Deutsch dari University of Oxford, dan Richard P. Feynman dari California
Institute of Technology (Caltech). Ide mereka adalah untuk membuat
sebuah komputer masa depan yang disebut dengan komputer kuantum.
Komputer
kuantum adalah alat hitung yang menggunakan sebuah fenomena mekanika kuantum, misalnya superposisi dan keterkaitan, untuk melakukan operasi data. Dalam komputasi klasik,
jumlah data dihitung dengan bit dalam komputer kuantum, hal ini dilakukan dengan qubit. Prinsip dasar komputer kuantum adalah bahwa sifat kuantum
dari partikel dapat digunakan untuk mewakili data dan struktur data, dan bahwa
mekanika kuantum dapat digunakan untuk melakukan operasi dengan data ini. Dalam
hal ini untuk mengembangkan komputer dengan sistem kuantum diperlukan suatu
logika baru yang sesuai dengan prinsip kuantum.
Jika dilihat dari kemampuannya,
komputer kuantum memiliki pemrosesan data yang sangat cepat melebihi komputer yang
ada saat ini. Jika komputer saat ini membutuhkan waktu 1025 tahun untuk memproses
data, maka komputer kuantum hanya perlu waktu 20 menit saja. Hal inilah yang
membuat para ilmuwan tertarik untuk mengembangkannya untuk digunakan di masa
depan.
ALGORITMA SHOR
Dengan
sistem logika yang baru, para ilmuwan harus memikirkan sebuah algoritma yang
berbeda untuk memproses informasi. Inilah yang sebenarnya merupakan inti dari
komputer kuantum. Beberapa algoritma telah dikembangkan dan yang di antaranya
telah berhasil ditemukan adalah algoritma Shor yang ditemukan oleh Peter Shor
pada tahun 1995. Lewat algoritma Shor ini, sebuah komputer kuantum dapat
memecahkan sebuah kode rahasia yang saat ini secara umum digunakan untuk
mengamankan pengiriman data. Kode ini disebut kode RSA. Jika disandikan melalui
kode RSA, data yang dikirimkan akan aman karena kode RSA tidak dapat dipecahkan
dalam waktu yang singkat. Selain itu, pemecahan kode RSA membutuhkan kerja
ribuan komputer secara paralel sehingga kerja pemecahan ini tidaklah efektif.
Sebagai
contoh, seorang pemecah kode akan membutuhkan waktu 8 bulan dan 1.600 pengguna
internet jika ia akan memecahkan kode RSA yang disandikan dalam 129 digit. Jika
hal ini mungkin, pengirim data hanya perlu menambahkan digit pada kode RSA-nya
agar para pemecah kode membutuhkan waktu yang lebih lama lagi untuk memecahkan
kuncinya. Sebagai gambaran, pemecahan kode RSA 140 (140 digit) akan membutuhkan
waktu yang lebih lama dari umur alam semesta (15 miliar tahun). Namun, jika
pemecah kode menggunakan komputer kuantum, mereka dapat memecahkan kode RSA 140
hanya dalam waktu beberapa detik. Hal inilah yang membuat waswas para pengguna
channel komunikasi rahasia saat ini untuk melakukan pengiriman data secara
aman.
QUANTUM GATES
Quantum Gates adalah sebuah gerbang kuantum yang
dimana berfungsi mengoperasikan bit yang terdiri dari 0 dan 1 menjadi qubits.
dengan demikian Quantum gates mempercepat banyaknya perhitungan bit pada waktu
bersamaan. Quantum Gates adalah blok bangunan sirkuit kuantum, seperti klasik
gerbang logika yang untuk sirkuit digital konvensional.
Quantum Gates / Gerbang Quantum merupakan sebuah
aturan logika / gerbang logika yang berlaku pada quantum computing. Prinsip
kerja dari quantum gates hampir sama dengan gerbang logika pada komputer
digital. Jika pada komputer digital terdapat beberapa operasi logika seperti
AND, OR, NOT, pada quantum computing gerbang quantum terdiri dari beberapa
bilangan qubits, sehingga quantum gates lebih susah untuk dihitung daripada
gerang logika pada komputer digital.
Untuk memanipulasi sebuah qubit, maka menggunakan
Quantum Gates (Gerbang Kuantum). Cara kerjanya yaitu sebuah gerbang kuantum
bekerja mirip dengan gerbang logika klasik. Gerbang logika klasik mengambil bit
sebagai input, mengevaluasi dan memproses input dan menghasilkan bit baru
sebagai output.
PENERAPAN QUANTUM COMPUTATION
Pada 19 Nov 2013 Lockheed Martin , NASA dan
Google semua memiliki satu misi yang sama yaitu mereka semua membuat komputer
kuantum sendiri . Komputer kuantum ini adalah superkonduktor chip yang
dirancang oleh sistem D - gelombang dan yang dibuat di NASA Jet Propulsion
Laboratories .
NASA dan Google berbagi sebuah komputer
kuantum untuk digunakan di Quantum Artificial Intelligence Lab menggunakan 512
qubit D -Wave Two yang akan digunakan untuk penelitian pembelajaran mesin yang
membantu dalam menggunakan jaringan syaraf tiruan untuk mencari set data astronomi
planet ekstrasurya dan untuk meningkatkan efisiensi searchs internet dengan
menggunakan AI metaheuristik di search engine heuristical .
A.I. seperti metaheuristik dapat menyerupai
masalah optimisasi global mirip dengan masalah klasik seperti pedagang keliling
, koloni semut atau optimasi swarm , yang dapat menavigasi melalui database
seperti labirin . Menggunakan partikel terjerat sebagai qubit , algoritma ini
bisa dinavigasi jauh lebih cepat daripada komputer konvensional dan dengan
lebih banyak variabel .
Dengan menggunakan desentralisasi ,
segerombolan kuantum AI , dimungkinkan untuk mensimulasikan perilaku muncul
juga, seperti Langton itu semut , yang bisa melihat munculnya kecerdasan
simulasi berbasis kuantum yang bisa pergi sejauh untuk menciptakan robot
selular realistis pada komputer .
Penggunaan metaheuristik canggih pada fungsi
heuristical lebih rendah dapat melihat simulasi komputer yang dapat memilih sub
rutinitas tertentu pada komputer sendiri untuk memecahkan masalah dengan cara
yang benar-benar cerdas . Dengan cara ini mesin akan jauh lebih mudah
beradaptasi terhadap perubahan data indrawi dan akan mampu berfungsi dengan
jauh lebih otomatisasi daripada yang mungkin dengan komputer normal.
Selain itu, dimungkinkan untuk menggunakan
metaheuristik untuk melakukan koreksi kesalahan pada perangkat lunak
menggunakan jaringan syaraf tiruan dengan membandingkan pemecahan sebuah
komputer kuantum dengan perangkat lunak program reguler dari komputer biasa masalah
dioptimalkan . Karena komputer biasa tidak kuantum mekanik , mereka harus
diprogram klasik . Namun, dengan menggunakan metaheuristik kuantum dimungkinkan
untuk melakukan optimasi masalah menggunakan kecerdasan buatan pada sebuah
komputer kuantum dan kemudian dibandingkan dengan arsitektur baris perintah
dalam software konvensional pada komputer klasik , yang mungkin terlalu rumit
untuk memodifikasi atau untuk memeriksa untuk kesalahan menggunakan perangkat
lunak insinyur manusia .
Referensi :
Komputer Kuantum
Andi Muhadir
Amin , Muhammad Ridwan
Email : ridwanm875@gmail.com, andima8@yahoo.co.id
Jurusan Teknik
Informatika, Fakultas Teknologi Industri Universitas Gunadrama
Abstraksi
Big
Data merupakan kumpulan data yang volume datanya super besar,
memiliki
keragaman sumber data yang tinggi, sehingga perlu dikelola dengan
metode dan
perangkat bantu yang kinerjanya sesuai. Jurnal ini akan diawali
dengan
pengertian dan karakteristik Big Data. Selanjutnya akan dipaparkan
faktor-faktor yang mempengaruhi terdapat
dalam Big Data, serta berbagai
contoh pemanfaatan teknologi Big Data dalam berbagai
bidang.
Kata kunci : Big Data, Data, Bidang
I.
Pendahuluan
Dalam era
globalisasi sekarang ini, manusia dapat mengakses segala informasi secara cepat
dan dapat diakses dimanapun. Dengan kemudahan tersebut, maka akan semakin
banyak manusia yang akan menyimpan datanya. Hal ini akan membuat volume sebuah
data yang digunakan manusia menjadi semakin besar dan biasanya datanya tidak
terstruktur, hal inilah yang disebut dengan big
data. Big data sudah mulai diterapkan oleh beberapa perusahaan besar,
dimana tidak hanya besar data yang menjadi poin utama melainkan apa yang akan
dilakukan dengan data tersebut. Big data inilah yang nantinya akan digunakan
sebagai analisis untuk wawasan yang mengarah pada pengambilan keputusan yang
lebih baik.
II.
Tinjauan Pustaka
a.
Big Data
Big Data adalah istilah umum untuk
segala himpunan data (data set) dalam jumlah yang sangat besar, rumit dan tak terstruktur
sehingga menjadikannya sukar ditangani apabila hanya menggunakan perkakas
manajemen basis
data biasa atau aplikasi pemroses data tradisional belaka.
Big Data masih
terbilang baru dan sering disebut sebagai tindakan pengumpulan dan penyimpanan
informasi yang besar untuk analisis. Fenomena Big Data, dimulai pada tahun 2000-an
ketika seorang analis industri Doug Laney menyampaikan konsep Big Data yang
terdiri dari tiga bagian penting, diantaranya:
·
Volume Organisasi mengumpulkan data dari berbagai sumber, termasuk
transaksi bisnis, media sosial dan informasi dari sensor atau mesin. Di masa
lalu, aktivitas semacam ini menjadi masalah, namun dengan adanya teknologi baru
(seperti Hadoop) bisa meredakan masalah ini.
·
Kecepatan Aliran data harus ditangani dengan secara cepat dan tepat bisa
melalui hardware maupun software. Teknologi hardware seperti tag RFID, sensor
pintar lainnya juga dibutuhkan untuk menangani data yang real-time.
·
Variasi Data yang dikumpulkan mempunyai format yang berbeda-beda. Mulai
dari yang terstruktur, data numerik dalam database tradisional, data dokumen
terstruktur teks, email, video, audio, transaksi keuangan dan lain-lain.
·
Variabilitas Selain kecepatan pengumpulan data yang meningkat dan
variasi data yang semakin beraneka ragam, arus data kadang tidak konsisten
dalam periode tertentu. Salah satu contohnya adalah hal yang sedang tren di
media sosial. Periodenya bisa harian, musiman, dipicu peristiwa dadakan dan
lain-lain. Beban puncak data dapat menantang untuk analis Big Data, bahkan
dengan data yang tidak terstruktur.
·
Kompleksitas Hari ini, data berasal dari berbagai sumber sehingga cukup
sulit untuk menghubungkan, mencocokan, membersihkan dan mengubah data di
seluruh sistem. Namun, Big Data sangat dibutuhkan untuk memiliki korelasi antar
data, hierarki dan beberapa keterkaitan data lainnya atau data yang acak
III.
Pembahasan
 |
| Sumber: http://noviardisyamsuir.blogspot.co.id/2016/03/contoh-big-data-di-berbagai-bidang.html |
Dalam kehidupan
sehari-hari, kita sudah bisa melihat sebuah big data yang dapat digunakan oleh
perusahaan-perusahaan untuk menganalisis data tersebut. Berikut ini adalah contoh
pemanfaatan big data yang bisa digunakan dalam berbagai bidang :
·
Perusahaan ritel dapat menggunakan informasi
dari social media seperti Facebook, Twitter, Google+ untuk menganalisis
bagaimana perilaku, persepsi pelanggan terhadap suatu produk atau brand dari
perusahan.
·
Perusahan manufaktur dapat memantau kondisi
peralatan setiap saat (real-time), sehingga dapat memperkirakan waktu terbaik
untuk mengganti peralatan. Karena mengganti terlalu cepat akan
merugikan/buang-buang uang atau kalau terlambat akan menyebabkan produksi
terganggu karena kerusakan peralatan.
·
Perusahaan manufaktur juga bisa memantau
produk yang baru launching melalui social sedia untuk mengetahui apakah ada
isu after-sales sehingga dapat mencegah kegagalan
garansi yang menyebabkan publikasi besar yang dapat merusak citra produk dan
perusahaan.
·
Perusahaan periklanan dapat menggunakan
informasi dari social media untuk mengetahui tanggapan terhadap promosi/iklan
yang baru diluncurkan.
·
Rumah sakit dapat merekam catatan medis
pasien sehingga big data tersebut bisa digunakan untuk menganalisis kecenderungan
sakit pasien
·
Pemerintahan dapat menggunakan informasi dari
social media untuk mengetahui tingkat kepuasan masyarakat terhadap pemerintah.
·
Jasa Keuangan dapat menggunakan analisis big
data untuk melihat aplikasi asuransi yang dapat segera diproses, dan mana yang
perlu divalidasi dengan dilakukan kunjungan oleh agen asuransi.
·
Jasa Perbankan dapat menggunakan rekaman
transaksi nasabah untuk mengetahui kemungkinan adanya kegiatan kejahatan
seperti pencucian uang, atau juga untuk merekam catatan kebiasaan karyawan
dalam rangka mendeteksi kemungkinan fraud.
·
Tim olahraga dapat menggunakan big data
untuk tracking penjualan tiket, mengetahui kondisi
pemain dan probabilitas akan mengalami cedera dan bahkan strategi bermain dari
tim.
Di Indonesia, kemampuan dari Big Data dapat
dimanfaatkan dalam beberapa hal diantaranya :
·
Pemanfaatan dalam bidang Pertanian
Pada
bagian pertanian ini, peneliti bisa mengambil sebuah data mulai dari kondisi
tanah, cuaca, memperhatikan pertumbuhan sebuah tanaman dalam jangka waktu
tertentu. Data tersebut nantinya akan dikumpulkan dan dianalisis. Hal ini
tentunya akan membantu para petani untuk menentukan kondisi seperti apa yang
akan membuat tanaman menjadi lebih subur dan menghasilkan hasil yang lebih baik.
·
Pemanfaatan dalam bidang Perpajakan
Penggunaannya
pada bidang perpajakan di Indonesia ini sebenarnya masih dalam tahap
pengembangan. Pada sistem pajak online, data yang didapat terbilang sangat
detail. Data tersebut kemudian divisualisasikan seperti silsilah keluarga,
jenis dan barang kekayaan apa saja yang dimiliki, serta jenis pajak dan status
apakah sudah melakukan pembayaran atau belum dari setiap orang yang memiliki
wajib pajak di Indonesia.
Dengan
data-data tersebutlah pemerintah bisa memanfaatkan untuk mengoptimalisasi
pendapatan negara dengan pajak.
·
Pemanfaatan dalam bidang Kesehatan
Pada
bidang kesehatan, data-data yang ada dari setiap pasien yang sakit mulai dari
klinik, puskesmas sampai rumah sakit akan dikumpulkan, diolah dan akan
dianalisis. Dengan begitu, semua informasi kesehatan penduduk Indonesia akan
menjadi terpusat. Hal ini akan memudahkan pemerintah untuk dapat melihat
tingkat kesehatan seluruh penduduk Indonesia juga pemerintah dapat melakukan
prediksi terhadap penyakit yang ada di Indonesia.
IV.
Kesimpulan
Big data merupakan sebuah volume
data yang sangat besar dan merupakan yang memiliki informasi yang sangat lengkap
dan terperinci. Dengan adanya data tersebut, baik perusahaan, pemerintah, ataupun
sebuah organisasi akan mendapat sebuah data yang nantinya bisa diolah dan digunakan
untuk analisis dimana hasil analisis tersebut akan digunakan untuk membuat
sebuah prediksi kan berbagai hal yang dibutuhkan.
Referensi
Pemanfaatan Big Data dalam berbagai bidang
CLOUD COMPUTING
Komputasi awan (Cloud Computing) adalah gabungan pemanfaatan
teknologi komputer ('komputasi') dan pengembangan berbasis Internet ('awan').
Awan (cloud) adalah metafora dari internet, sebagaimana awan yang sering
digambarkan di diagram jaringan komputer. Sebagaimana awan dalam diagram
jaringan komputer tersebut, awan (cloud) dalam Cloud Computing juga merupakan
abstraksi dari infrastruktur kompleks yang disembunyikannya. Ia adalah suatu
metoda komputasi di mana kapabilitas terkait teknologi informasi disajikan
sebagai suatu layanan (as a service), sehingga pengguna dapat mengaksesnya
lewat Internet ("di dalam awan") tanpa mengetahui apa yang ada
didalamnya, ahli dengannya, atau memiliki kendali terhadap infrastruktur
teknologi yang membantunya. Menurut sebuah makalah tahun 2008 yang dipublikasi
IEEE Internet Computing "Cloud Computing adalah suatu paradigma di mana
informasi secara permanen tersimpan di server di internet dan tersimpan secara
sementara di komputer pengguna (client) termasuk di dalamnya adalah desktop,
komputer tablet, notebook, komputer tembok, handheld, sensor-sensor, monitor
dan lain-lain.
Komputasi awan adalah suatu konsep umum yang mencakup SaaS,
Web 2.0, dan tren teknologi terbaru lain yang dikenal luas, dengan tema umum berupa
ketergantungan terhadap Internet untuk memberikan kebutuhan komputasi pengguna.
Sebagai contoh, Google Apps menyediakan aplikasi bisnis umum secara daring yang
diakses melalui suatu penjelajah web dengan perangkat lunak dan data yang
tersimpan di server. Komputasi awan saat ini merupakan trend teknologi terbaru,
dan contoh bentuk pengembangan dari teknologi Cloud Computing ini adalah
iCloud.
Sejarah Cloud Computing
Pada tahun 50-an, Cloud Computing memiliki konsep yang
mendasar. Ketika komputer mainframe yang tersedia dalam skala yang besar dalam
dunia pendidikan dan perusahaan dapat diakses melalui komputer terminal disebut
dengan Terminal Statis. Terminal tersebut hanya dapat digunakan untuk melakukan
komunikasi tetapi tidak memiliki kapasitas pemrosesan internal. Agar penggunaan
mainframe yang relatif mahal menjadi efisien maka mengembangkan akses fisik
komputer dari pembagian kinerja CPU. Hal ini dapat menghilangkan periode tidak
aktif pada mainframae, memungkinkan untuk kembali pada investasi. Hinga
pertengahan tahun 70-an dikenal dengan RJE remote proses Entry Home Job yang
berkaitan besar dengan IBM dan DEC Mainframe.
Tahun 60-an, John McCarthy berpendapat bahwa “Perhitungan
suatu hari nanti dapat diatur sebagai utilitas publik.” Di buku Douglas
Parkhill, The Challenge of the Computer Utility menunjukkan perbandingan
idustri listrik dan penggunaan pada listrik di masyarakat umum dan pemerintahan
dalam penyediaan cloud computing. Ketika Ilmuan Herb Grosch mendalilkan bahwa
seluruh dunia akan beroperasi pada terminal bodah didukung oleh sekitar 15
pusat data yang besar. Karena komputer ini sangat canggih, banyak perusahaan
dan entitas lain menyediakan sendiri kemampuan komputasi melalui berbagai waktu
danbeberapa organisasi, seperti GE GEISCO, Anak perusahaan IBM Biro
Corporation, Tymshare, CSS Nasional, Data Dial, Bolt, dan Beranek and Newman.
Tahun 90-an, perusahaan telekomunikasi mulai menawarkan VPN,
layanan jaringan pribadi dengan kualitas sebanding pelayanannya, tapi dengan
biaya yang lebih rendah. Karena merasa cocok dengan hal tersebut untuk
menyeimbangkan penggunaan server, mereka dapat menggunakan bandwidth jaringan
secara keseluruhan. Lalu menggunakan simbol awan sebagai penunjuk titik
demarkasi antara penyedia dan pengguna yang saling bertanggung jawab. Cloud
computing memperluas batas ini untuk menutup server serta infrastruktur
jaringan.
Sejak Tahun 2000, Amazon sebagai peran penting dalam semua
pengembangan cloud computing dengan memodernisasi pusat data, seperti jaringan
komputer yang menggunakan sesedikit 10% dari kapasitas mereka pada satu waktu.
Setelah menemukan asitektur awan baru, mengalami peningkatan efisiensi internal
sedikit bergerak capat “Tim Dua-Pizza” (Tim kecil untuk memberi makan dengan
dua pizza) dapat menambahkan fitur baru dengan cepat dan lebih mudah. Kemudian
Amazon mulai mengembangkan produk baru sebagai penyedia cloud computing untuk
pelanggan eksternalm dan meluncurkan Amzaon Web Service (AWS) tahun 2006.
Awal tahun 2008, Eucalypus menjadi yang pertama open source,
AWS API Platform yang kompatibel menyebarkan awan swasta. Open Nebula
ditingkatkan dalam proyek Eropa Reservoir Komisi yang sudah didanai. Pada tahun
yang sama, agar difokuskan pada penyediaan jaminan kualitas layanan (seperti
yang dipersyaratkan oleh aplikasi interaktif real-time) untuk infrastruktur
berbasis cloud dalam rangka IRMOS Eropa Proyek yang didanai Komisi. Pertengahan
2008, Gartner melihat kesempatan untuk membentuk hubungan antara konsumen
layanan TI, mereka menggunakan layanan TI dan menjualnya. Dan mengamati bahwa
“Organisasi layanan TI yang beralih dari perangkat keras milik perusahaan dan
aset perangkat lunak untuk digunakan layanan berbasis model sehingga pergeseran
diproyeksikan untuk komputasi.....akan menghasilkan pertumbuhan dramatis dalam
produk IT di beberapadaerahdan pengurangan yang signifikan di daerah lain.”.
Tanggal 1 Maret 2011,IBM mengumumkan SmartCloud kerangka IBM
Smarter Planet untuk mendukung. Di antara berbagai komponen dasar Smarter
Computing, cloud computing adalah bagian yang paling penting.
Manfaat Cloud Computing
Dari penjelasan tentang cloud computing diatas, ada banyak
manfaat yang bisa kita ambil dari cloud computing, yaitu :
- Skalabilitas, yaitu dengan cloud computing kita bisa menambah kapasitas penyimpanan data kita tanpa harus membeli peralatan tambahan, misalnya hardisk dll. Kita cukup menambah kapasitas yang disediakan oleh penyedia layanan cloud computing.
- Aksesibilitas, yaitu kita bisa mengakses data kapanpun dan dimanapun kita berada, asal kita terkoneksi dengan internet, sehingga memudahkan kita mengakses data disaat yang penting.
- Keamanan, yaitu data kita bisa terjamin keamanan nya oleh penyedia layanan cloud computing, sehingga bagi perusahaan yang berbasis IT, data bisa disimpan secara aman di penyedia cloud computing. Itu juga mengurangi biaya yang diperlukan untuk mengamankan data perusahaan.
- Kreasi, yaitu para user bisa melakukan/mengembangkan kreasi atau project mereka tanpa harus mengirimkan project mereka secara langsung ke perusahaan, tapi user bisa mengirimkan nya lewat penyedia layanan cloud computing.
- Kecemasan, ketika terjadi bencana alam data milik kita tersimpan aman di cloud meskipun hardisk atau gadget kita rusak.
Layanan Cloud Computing
- · Infrastructure as a Service (IaaS)
Infrastructure as a Service adalah layanan komputasi awan
yang menyediakan infrastruktur IT berupa CPU, RAM, storage, bandwith dan
konfigurasi lain. Komponen-komponen tersebut digunakan untuk membangun komputer
virtual. Komputer virtual dapat diinstal sistem operasi dan aplikasi sesuai
kebutuhan. Keuntungan layanan IaaS ini adalah tidak perlu membeli komputer
fisik sehingga lebih menghemat biaya. Konfigurasi komputer virtual juga bisa
diubah sesuai kebutuhan. Misalkan saat storage hampir penuh, storage bisa
ditambah dengan segera. Perusahaan yang menyediakan IaaS adalah Amazon EC2,
TelkomCloud dan BizNetCloud.
- · Software as a Service (SaaS)
Software as a Service adalah layanan komputasi awan dimana
kita bisa langsung menggunakan aplikasi yang telah disediakan. Penyedia layanan
mengelola infrastruktur dan platform yang menjalankan aplikasi tersebut. Contoh
layanan aplikasi email yaitu gmail, yahoo dan outlook sedangkan contoh aplikasi
media sosial adalah twitter, facebook, dan google+. Keuntungan dari layanan ini
adalah pengguna tidak perlu membeli lisensi untuk mengakses aplikasi tersebut.
Pengguna hanya membutuhkan perangkat klien komputasi awan yang terhubung ke
internet. Ada juga aplikasi yang mengharuskan pengguna untuk berlangganan agar
bisa mengakses aplikasi yaitu Office 365 dan Adobe Creative Cloud.
- · Platform as a Service (PaaS)
Platform as a Service adalah layanan yang menyediakan
computing platform. Biasanya sudah terdapat sistem operasi, database, web
server dan framework aplikasi agar dapat menjalankan aplikasi yang telah
dibuat. Perusahaan yang menyediakan layanan tersebutlah yang bertanggung jawab
dalam pemeliharaan computing platform ini. Keuntungan layanan PaaS ini bagi
pengembang adalah mereka bisa fokus pada aplikasi yang mereka buat tanpa
memikirkan tentang pemeliharaan dari computing platform. Contoh penyedia
layanan PaaS adalah Amazon Web Service dan Windows Azure.
Metoda atau Cara Kerja Cloud Computing
Berikut merupakan cara kerja penyimpanan data dan replikasi
data pada pemanfaatan teknologi cloud computing. Dengan Cloud Computing
komputer lokal tidak lagi harus menjalankan pekerjaan komputasi berat untuk
menjalankan aplikasi yang dibutuhkan, tidak perlu menginstal sebuah paket
perangkat lunak untuk setiap komputer, kita hanya melakukan installasi operating
system pada satu aplikasi. Jaringan komputer yang membentuk awan (internet)
menangani mereka sebagai gantinya. Server ini yang akan menjalankan semuanya
aplikasi mulai dari e-mail, pengolah kata, sampai program analisis data yang
kompleks. Ketika pengguna mengakses awan (internet) untuk sebuah website
populer, banyak hal yang bisa terjadi. Pengguna Internet Protokol (IP) misalnya
dapat digunakan untuk menetapkan dimana pengguna berada (geolocation). Domain
Name System (DNS) jasa kemudian dapat mengarahkan pengguna ke sebuah cluster
server yang dekat dengan pengguna sehingga situs bisa diakses dengan cepat dan
dalam bahasa lokal mereka. Pengguna tidak login ke server, tetapi mereka login
ke layanan mereka menggunakan id sesi atau cookie yang telah didapatkan yang
disimpan dalam browser mereka. Apa yang user lihat pada browser biasanya datang
dari web server. Webservers menjalankan perangkat lunak dan menyajikan pengguna
dengan cara interface yang digunakan untuk mengumpulkan perintah atau instruksi
dari pengguna (klik, mengetik, upload dan lain-lain) Perintah-perintah ini
kemudian diinterpretasikan oleh webservers atau diproses oleh server aplikasi.
Informasi kemudian disimpan pada atau diambil dari database server atau file
server dan pengguna kemudian disajikan dengan halaman yang telah diperbarui.
Data di beberapa server disinkronisasikan di seluruh dunia untuk akses global
cepat dan juga untuk mencegah kehilangan data.
Web service telah memberikan mekanisme umum untuk pengiriman
layanan, hal ini membuat service-oriented architecture (SOA) ideal untuk
diterapkan. Tujuan dari SOA adalah untuk mengatasi persyaratan yang bebas
digabungkan, berbasis standar, dan protocol-independent distributed computing.
Dalam SOA, sumber daya perangkat lunak yang dikemas sebagai
"layanan," yang terdefinisi dengan baik, modul mandiri yang
menyediakan fungsionalitas bisnis standar dan konteks jasa lainnya. Kematangan
web service telah memungkinkan penciptaan layanan yang kuat yang dapat diakses
berdasarkan permintaan, dengan cara yang seragam.
Implementasi Cloud Computing
Ada tiga poin utama yang diperlukan dalam implementasi cloud
computing, yaitu :
- · Computer front end
- · Biasanya merupakan computer desktop biasa.
- · Computer back end
Computer back end dalam skala besar biasanya berupa server
computer yang dilengkapi dengan data center dalam rak-rak besar. Pada umumnya
computer back end harus mempunyai kinerja yang tinggi, karena harus melayani
mungkin hinggga ribuan permintaan data. Penghubung keduanya bisa berupa
jaringan LAN atau internet.
Karakteristik Cloud Computing
1) On-Demand Self-Services
Sebuah layanan cloud computing harus dapat dimanfaatkan oleh
pengguna melalui mekanisme swalayan dan langsung tersedia pada saat dibutuhkan.
Campur tangan penyedia layanan adalah sangat minim. Jadi, apabila kita saat ini
membutuhkan layanan aplikasi CRM (sesuai contoh di awal), maka kita harus dapat
mendaftar secara swalayan dan layanan tersebut langsung tersedia saat itu juga.
2) Broad Network Access
Sebuah layanan cloud computing harus dapat diakses dari mana
saja, kapan saja, dengan alat apa pun, asalkan kita terhubung ke jaringan
layanan. Dalam contoh layanan aplikasi CRM di atas, selama kita terhubung ke
jaringan Internet, saya harus dapat mengakses layanan tersebut, baik itu
melalui laptop, desktop, warnet, handphone, tablet, dan perangkat lain.
3) Resource Pooling
Sebuah layanan cloud computing harus tersedia secara
terpusat dan dapat membagi sumber daya secara efisien. Karena cloud computing
digunakan bersama-sama oleh berbagai pelanggan, penyedia layanan harus dapat
membagi beban secara efisien, sehingga sistem dapat dimanfaatkan secara
maksimal.
4) Rapid Elasticity
Sebuah layanan cloud computing harus dapat menaikkan (atau
menurunkan) kapasitas sesuai kebutuhan. Misalnya, apabila pegawai di kantor
bertambah, maka kita harus dapat menambah user untuk aplikasi CRM tersebut
dengan mudah. Begitu juga jika pegawai berkurang. Atau, apabila kita
menempatkan sebuah website berita dalam jaringan cloud computing, maka apabila
terjadi peningkatkan traffic karena ada berita penting, maka kapasitas harus
dapat dinaikkan dengan cepat.
5) Measured Service
Sebuah layanan cloud computing harus disediakan secara
terukur, karena nantinya akan digunakan dalam proses pembayaran. Harap diingat
bahwa layanan cloud computing dibayar sesuai penggunaan, sehingga harus terukur
dengan baik.
Kelebihan dan Kekurangan Cloud Computing
A. Kelebihan
- · Menghemat biaya investasi awal untuk pembelian sumber daya.
- · Bisa menghemat waktu sehingga perusahaan bisa langsung fokus ke profit dan berkembang dengan cepat.
- · Membuat operasional dan manajemen lebih mudah karena sistem pribadi/perusahaan yang tersambung dalam satu cloud dapat dimonitor dan diatur dengan mudah.
- · Menjadikan kolaborasi yang terpercaya dan lebih rampingsistem informasi yang dibangun.
B. Kekurangan
Komputer akan menjadi lambat atau tidak bisa dipakai sama
sekali jika internet bermasalah atau kelebihan beban. Dan juga perusahaan yang
menyewa layanan dari cloud computing tidak punya akses langsung ke sumber daya.
Jadi, semua tergantung dari kondisi vendor/penyedia layanan cloud computing.
Jika server vendor rusak atau punya layanan backup yang buruk, maka perusahaan
akan mengalami kerugian besar.
Contoh Cloud Computing
1. Google Drive
Google Drive adalah layanan penyimpanan Online yang dimiliki
Google. Google Drive diluncurkan pada tanggal 24 April 2012. Sebenarnya Google
Drive merupakan pengembangan dari Google Docs. Google Drive memberikan
kapasitas penyimpanan sebesar 5GB kepada setiap penggunanya. Kapasitas tersebut
dapat ditambahkan dengan melakukan pembayaran atau pembelian Storage.
Penyimpanan file di Google Drive dapat memudahkan pemilik file dapat mengakses
file tersebut kapanpun dan dimanapun dengan menggunakan komputer desktop,
laptop, komputer tablet ataupun smartphone. File tersebut juga dapat dengan
mudah dibagikan dengan orang lain untuk berbagi pakai ataupun melakukan
kolaborasi dalam pengeditan.
2. Windows Azure
Windows Azure adalah sistem operasi yang berbasis komputasi
awan, dibuat oleh Microsoft untuk mengembangkan dan mengatur aplikasi serta
melayani sebuah jaringan global dari Microsoft Data Centers. Windows Azure yang
mendukung berbagai macam bahasa dan alat pemograman. Sistem operasi ini dirilis
pada 1 Februari 2010.
3. Google App Engine
Tujuan utama Google App Engine ( GAE ) adalah mengefisienkan
pengguna menjalankan aplikasi web. Arsitektur dari Google App EngineGoogle App
Engine mempertahankan Python dan lingkungan runtime Java pada server aplikasi,
bersana dengan beberapa Application Programming Interface sederhana untuk
mengakses layanan google.
Sumber:
1. http://id.wikipedia.org/wiki/Komputasi_awan
2. http://maulanaichwan.blogspot.com/2012/12/makalah-cloud-computing.html
Cloud Computing
Langganan:
Komentar
(
Atom
)







